 |
 |
Архитектура, функциональность и назначение Т-системы
Динамическое распараллеливание программ на базе параллельной редукции графов Назначение, функциональность и архитектура Т-системы Институт программных систем РАН Центр телекоммуникаций и технологий Интернет МГУ им. М.В. Ломоносова Назначение Т-системыТ-система - среда программирования с поддержкой автоматического динамического распараллеливания программ. Для реализации концепции автоматического динамического распараллеливания программ в Т-системе предложена новая модель организации вычислительного процесса, основанная на следующих базовых принципах:
В качестве основной парадигмы рассматривается функциональное программирование. Программа представляет собой набор чистых функций. Каждая функция может иметь несколько аргументов и несколько результатов.
В то же время тела функций могут быть описаны в императивном стиле (на языках типа FORTRAN, C и т. п.) Важно только, чтобы: * Всю информацию извне функция получала только через свои аргументы; * Вся информация из функции передавалась только через явно описанные результаты.
Вызов функции G, производимый в процессе вычисления функции F выполняется нетрадиционным способом (т. н. сетевой вызов функции). При этом порождается новый процесс с несколькими входами (в соответствии с числом аргументов функции G) и несколькими выходами (в соответствии с числом результатов функции G). Выходы нового процесса связываются с соответствующими переменными процесса F отношением ╬поставщик - потребитель© , и тем самым, переменные-потребители принимают неготовые (не вычисленные) значения. Порожденный процесс G должен вычислить функцию G и заменить неготовые значения у всех своих потребителей на соответствующие результаты функции G.
Функциональность Т-системы * ╬За© и ╬против© функционального подхода * Система инвариантов Т-системы * Теоремы (Черча-Россера и др.) * Параллельная редукция графов * Расширения классической схемы * Мемоизация ╬За© и ╬против© функционального подходаСледующая программа, написанная на языке Haskell, вычисляет все возможные способы получить число 100 расстановкой арифметических операций и скобок между несколькими цифрами номера билета (в качестве примера использования программы приведен ее запуск для числа 314159):
tickets ds = (ds, foldl (\n c -> 10*n + digitToInt c) 0 ds) :
[("("++ld++[op]++rd++")", f lv rv) |
(op,f) <- [('+',(+)),('-',(-)),('*',(*)),('/',(div))],
n<-[1..length ds-1],
(ld,lv) <- tickets (take n ds),
(rd,rv) <- tickets (drop n ds),
op /= '/' || (rv /= 0 && lv `mod` rv == 0)]
happy = map fst . (filter ((==)100 . snd)) . tickets
Hugs session for:
/usr/share/hugs/lib/Prelude.hs
ticket.hs
Type :? for help
Main> happy "314159"
["(3+(1+(4*(15+9))))","(31+((4*15)+9))","((3+1)+(4*(15+9)))",
"(((3*14)-1)+59)","((31+(4*15))+9)","((3*14)-(1-59))",
"((31*4)-(15+9))","(((31*4)-15)-9)","((3-1)*(4+(1+(5*9))))",
"((3-1)*((4+1)+(5*9)))"]
Main> [Leaving Hugs]
Следующая программа: Расстановка ферзей на доске N x N:
module Queens where
import Gofer
queens number_of_queens = qu number_of_queens where
qu 0 = [[]]
qu (m+1) = [ p++[n] | p<-qu m, n<-[1..number_of_queens], safe p n ]
safe p n = all not [ check (i,j) (m,n) | (i,j) <- zip [1..] p ]
where m = 1 + length p
check (i,j) (m,n) = j==n || (i+j==m+n) || (i-j==m-n)
q = putStr . layn . map show . queens
Система инвариантов Т-системы
* Редукция графов -- меняет граф, не меняет его значение
* Стратегия вычислений -- решает, что вычислять в первую очередь
* Распределение работы -- решает, какую задачу кому отдать
Теоремы (Черча-Россера и др.)
Теорема Черча-Россера Если R -- отношение, то пусть R означает его конечно-транзитивное замыкание. Пусть X Y означает, что X редуцируется в Y . Обозначим X cnv Y X Y Y X. Тогда: X cnv Y N : X N Y N
Теорема о единственности нормальной формы (следствие из т. Ч-Р) Любые две нормальные формы лямбда-выражения алфавитно-эквивалентны.
Ромбическое свойство Если выражение E может быть редуцировано к двум выражениям E1 и E2, то существует N, в которое могут быть редуцированы E1 и E2.
Теорема стандартизации Если выражение E имеет нормальную форму, то редукция самого левого из самых внешних редексов на каждом этапе редукции E гарантирует достижение этой нормальной формы с точностью до алфавитной эквивалентности.
Параллельная редукция графовНиже изложена краткая теоретическая база параллельной редукции графов лямбда-исчисление -- это исчисление анонимных (безымянных) функций. Оно дает, во-первых, метод представления функций и, во-вторых, множество правил вывода для синтаксического преобразования функций.
Редукция -- это процесс упрощения лямбда-выражения.
Редекс -- это редуцируемое выражение. лямбда-выражения могу быть представлены в виде графов. При этом множественные ссылки на одно и то же выражение аргумента представляются множеством дуг, идущих к единственной разделяемой копии соответствующего графа аргумента.
При редукции графа выражения вполне возможно присутствие в этом графе множества редексов в любой момент. Вследствии прозрачности ссылок мы знаем, что эти редексы будут всегда вычисляться с одинаковым результатом независимо от того, где и когда это вычисление имеет место. Поэтому вполне возможно вычислять их одновременно, разместив на отдельных процессорах. Каждый процессор может затем приступить к редукции соответствующих редексов, возможно генерируя новые процессы и, таким образом, создавая новые параллельные задачи. Ниже приведен алгоритм (весьма упрощеный), реализующий параллельную редукцию графов на языке Лисп:
;; Graph node definition
(defstruct (n)
(in) (out)
(fun) (val)
(thread)
(ct) (dt))
;; Main functions
(defun getfor (n)
(add-link *node* n)
(que-put n *cal*))
(defun forget (n)
(del-link *node* n)
(que-put n *col*))
(defun cal (n)
(or (null (n-out n))
(n-thread n)
(setf (n-thread n) (start-thread n))))
(defun col (n)
(or (n-out n)
(null (n-thread n))
(setf (n-thread n) (kill-thread n))))
(defun start (n)
(call-with-node n
(compute n))
(if (n-ct n) (funcall (n-ct n) n))
(mapcar #'kill-thread (n-out n)))
(defun stop (n)
(mapcar #'kill-thread (n-out n))
(if (n-dt n) (funcall (n-dt n) n))
(call-with-node n
(mapcar #'forget (n-in n))))
(provide 'magnate)
Расширения классической схемы
* Стратегии выбора и распределения работы
* Вызов по состоянию
* Подъем функциональной схемы
* Монотонные объекты
* Инкрементальные вычисления
Стратегии выбора и распределения работы
При вызове Т-функции имеется две возможности, что считать дальше:
-
Сначала считать ╬вширь©
Порождается больше пренатальных процессов, вычисления становятся более ╬ленивыми© и может потребоваться больше памяти для стеков
-
Сначала считать ╬вглубь©
Экономия на стеках и на кэше, вычисления становятся более ╬энергичными© и порождается меньше пренатальных процессов
Результатом работы функции может быть некоторая фиктивная величина, которая означает, что над глобальными данными произведено некоторое преобразование.
МемоизацияДля чистых функций (не имеющих побочных эффектов) можно запоминать результат их вычислений и затем при повторных вызовах от одних и тех же аргументов просто брать значение из таблицы.
Архитектура ПО Т-системы * Программный и пользовательский интерфейсы Т-системы * Ядро параллельной редукции графов * Кластерный уровень * Компилятор (source-to-source converter) * Работа в качестве вычислительного сервера * Приложения Программный и пользовательский интерфейсы Т-системы * Библиотека классов C++ и интерфейс с другими языками * Гладкие T-расширения языков C и Fortran * Среда для разработки, отладки и профилировки программ Библиотека классов C++ и интерфейс с другими языкамиВ качестве средства реализации ядра Т-системы выбран язык C++. Это обеспечивает хорошую эффективность и переносимость кода, а также упрощает достижение таких важных целей, как модульность и расширяемость ПО. В ряде случаев (например, для многих невычислительных задач), использование C++ также очень желательно и с точки зрения удобства разработки параллельных приложений.
Интерфейс Т-системы для разработчика ПО, программирующего на языке C++, выглядит как совокупность классов, которые он может гармонично включить в дизайн своего приложения и эффективно использовать все возможности Т-системы на всех уровнях распараллеливания, начиная от динамического распределения вычислительной нагрузки и заканчивая интерфейсами с клиентской стороной.
Гладкие T-расширения языков C и FortranВажным достоинством новой версии Т-системы является то, что она поддерживает гладкое расширение языка C. Гладким оно названо потому, что все необходимые конструкции для указания мест распараллеливания программы просто и естественно погружены в синтаксис языка C.
Компилятор преобразует программу на языке TC в программу на языке C. При этом он производит необходимый анализ программы и вставляет в текст все необходимые обращения к ядру Т-системы. Затем C-программа транслируется обычным оптимизирующим компилятором.
Ключевым свойством гладкого расширения языка является то, что программа на этом языке превращается в программу на языке C и без специального компилятора, если определить ключевые слова, добавленные в язык TC как макросы. Предполагается, что это удобство будет оценено пользователями, которым будет проще начинать разработку и переделку своих программ под Т-систему. TFortran: первая версия будет на базе f2c (Fortran-to-C конвертора).
Среда для разработки, отладки и профилировки программСреда разработки для Т-системы является надстройкой над средой разработки обычных последовательных программ.
Дополнения сделаны в следующих пунктах:
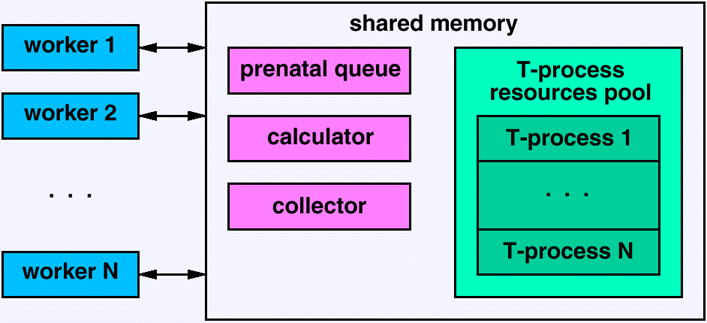
В систему управления памятью входят:
Внешнее вычисление узла графа:
Примеры, где внешние вычисления возникают:
Сопряжение с кластерным уровнемДля повышения эффективности преобразование в транспортную форму производится по необходимости.
ОтказоустойчивостьВ Т-системе предусмотрена возможность динамического изменения конфигурации. Исключение и подключение компьютера может происходить без остановки процесса вычислений, при условии что сетевой транспорт аппаратно это поддерживает.
Обеспечение отказоустойчивости:
В случае отказа узла соответствующие порталы терминируют внешнее вычисление узлов графа, с которыми они были связаны.
После этого узлы повторяют цикл вычисления, используя новую информацию, где отказавший узел уже отсутствует.
Кластерный уровень * Вычислительные пространства и порталы * Асинхронный ввод-вывод * Активные сообщения * Сопряжение с реализациями MPI/IMPI * Распределенная мемо-таблица * Внешнее планирование * Дерево вычислительных ресурсов * Начало и окончание работы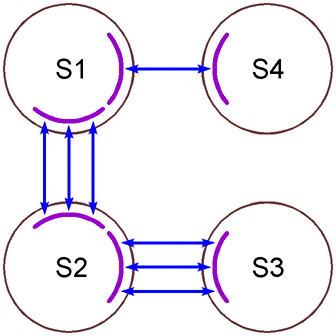
Два режима работы: реальный кластер и эмуляция кластера
Асинхронный ввод-вывод * Ввод-вывод как внешнее вычисление * Распараллеливание для одного и нескольких процессов Ввод-вывод как внешнее вычислениеАсинхронный ввод-вывод рассматривается как внешнее вычисление
Распараллеливание для одного и нескольких процессовPVFS обеспечивает распараллеливание ввода-вывода для одного процесса
(socket I/O - MPI)ROMIO подсистема MPICH, обеспечивающая асинхронный ввод-вывод для нескольких одновременно работающих процессов
Активные сообщения Распределенная мемо-таблицаDPMT - Distributed Parallel Memo Table
Глобальное разделяемое между вычислительными узлами отображение
{функция,аргументы} -> вершина редуцируемого графа
Сборка мусора:
Каждую запись добавляем в список с индексом, равным целой части логарифма его времени вычисления. Каждый список просматриваем через соответствующее время.
Внешнее планированиеВ процессе динамического распараллеливания может образовываться большое количество готовых к исполнению задач, значительно превышающее количество активных исполнителей (процессоров) в данном вычислительном узле.
Под внешним планированием понимается выбор узла кластера, на котором будет вычисляться данная функция.
Этот выбор осуществляется самим узлом графа на основе информации о производительности загруженности узлов кластера.
Дерево вычислительных ресурсовИнформация о производительности и загруженности узлов кластера хранится в дереве ресурсов.
При избытке готовых к исполнению вычислительных задач на одном вычислительном узле и недогруженности других узлов кластера происходит миграция задач на наиболее подходящий узел.
Узлы кластера обмениваются информацией (через широковешательные посылки) о своей загруженности и каждый узел лениво вычисляет статистику загрузки для каждого подкластера и всего кластера в целом (поддерживается иерархическая схема организации кластера). При избытке заданий узел, на который следует отправить задачу (например, пренатальный Т-процесс), должен вычисляться за несколько сотен инструкций процессора. Полная загруженность кластера должна обнаруживаться за несколько инструкций.
Начало и окончание работы Начало работы * mpirun {user-t-executable} * Запрос клиента Окончание работы * Вывод результата * Сбор статистики и финализация Компилятор (source-to-source converter) * Синтаксис и семантика языка TC * Подсчет аттрибутов * Оптимизация обращений к Т-ядру * Порождение C-кода и C-структур Синтаксис и семантика языка TC * Язык TC является гладким расширением языка C * Может быть откомпилирован как обычная C-программа * Добавлены новые атрибуты переменных и функций tval -- Т-переменная tptr -- указатель на Т-значение tarray -- Т-массив tfun -- Т-функция tlazy -- атрибут для ленивой семантики tmemo -- мемоизуемая функция tout -- результат Т-функции Подсчет аттрибутов Проход 1: подсчет атрибутов Оптимизация обращений к Т-ядру Проход 2: оптимизация обращений к ядру Т-системы Порождение C-кода и C-структур Работа в качестве вычислительного сервера * Сопряжение с прикладными программами * Средства обеспечения безопасности Работа в качестве вычислительного сервераДоступ к вычислительному ядру кластера осуществляется через выделенный компьютер, выполняющий роль шлюза, и работающий под управлением доработанной версией ОС Linux, в которой устранены наиболее узкие звенья в системе безопасности. Доступ пользователей к шлюзу осуществляется через протокол и систему аутентификации SSH, по этому же протоколу происходит поступление небольших объемов входных и выходных, а также управляющих данных. Это обеспечивает хорошую защищенность передаваемых данных, но накладывает ограничения на скорость обмена ввиду больших накладных расходов на криптостойкое кодирование и декодирование информации. Для передачи больших массивов может использоваться другая схема, основанная на пересылке данных, закрытых высокоскоростным алгоритмом шифрования с автоматически генерируемым случайным ключом значительной длины, который передается по хорошо защищенному протоколу SSH.
Сопряжение с прикладными программами * T-scripting languages * Интерпретатор комбинаторной логики * Параллельная реализация языка Рефал+ T-scripting languagesВ некоторых случаях удобно иметь специальный язык для оперативного формирования вычислительных задач. На такое средство программирования можно смотреть как на аналог shell'а в системе Unix, из которого можно вызывать базовые системные и пользовательские функции, написанные на языках ТC, TFortran и т. д.
По всему миру широко используются такие технологии, как TCL, и данный подход можно рассматривать как распространение этого хорошо зарекомендовавшего себя подхода на кластерные вычисления.
Основными отличиями shell для кластеров являются: * язык функциональный, имеет ленивую модель вычислений и поддерживает огромное количество параллельно выполняющихся потоков (вызовов функций); * динамически распараллеливает программы в кластере, используя специальные расширения Т-системы (системные функции ядра комбинаторы). Интерпретатор комбинаторной логикиКомбинатором называется лямбда-выражение без свободных переменных.
Любую чистую функцию можно представить в виде аппликативного выражения, состоящего только из S и K комбинаторов и примитивных функций.
K x y = x S f g x = (f x)(g x) I x = x I = S K K I x = (S K K) x = (K x) (K x) = x Y = S S K ( S ( K ( S S ( S ( S S K ) ) ) ) K ) Параллельная реализация языка Рефал+ * Реализован новый (непараллельный) рантайм для Рефала+ * Зафиксирован интерфейс для компиляции из Рефала+ в C++ * Смена рантайма не влечет за собой изменения компилятора и Рефал-библиотек * При параллельной реализации Рефал-рантайма значительное количество кода будет общим с рантаймом Т-системы Средства обеспечения безопасности * Организация и ограничение доступа * Распределение ресурсов между пользователями Организация и ограничение доступаНа управляющем компьютере находится также все основное и дополнительное ПО, которое может исполняться на вычислительных узлах кластера.
Часть функций по администрированию кластера выполняется только локально, причем для этого необходимы права суперпользователя на управляющем компьютере. К этим функциям относятся установка программных пакетов и библиотек, изменение распределения ресурсов для пользователей кластера, назначение администраторов.
В любой момент времени система может находится либо в штатном, либо в технологическом режиме.
В штатном режиме на вычислительных узлах кластера не предусмотрено никакой возможности получить привилегии суперпользователя. В системе нет никаких setuid-задач, и единственным управляющим элементом во время ее работы является специализированное и системное ПО, которое позволяет пользователям дистанционно запускать свои задачи на счет, а администраторам выполнять ряд дополнительных функций по контролю и распределению ресурсов кластера.
Переход в технологический режим осуществляется в несколько стадий. Сначала производится изменение статуса вычислительных узлов, что отражается в таблицах вычислительных ресурсов. Все вычислительные процессы оповещаются об этом изменении и принимают решения о миграции в то или иное вычислительное пространство. Наименьший приоритет имеет вторичная память, поскольку у нее скорость исполнения программы равна нулю.
По умолчанию система после загрузки находится в штатном режиме. В технологическом режиме имеется возможность администрирования кластера из локальной сети.
Распределение ресурсов между пользователями Всех пользователей можно условно разделить на две категории по уровню предо- ставляемого доступа: * Пользователи, которые могут вызывать лишь некоторые (предопределенные) Т-подпрограммы * Пользователи, которые могут запускать свои собственные Т-/MPI-программыЕсли в первом случае ограничения на возможности накладываются путем аккуратного программирования удаленного Т-интерфейса, то во втором случае необходима тщательная доработка системы квотирования ресурсов в ядре ОС Linux.
Приложения * Отладка и трассировка Т-программ * Примеры вычислительных задач * Примеры невычислительных задач * Диаграмма классов Т-системы * Аналоги Т-системы Отладка и трассировка Т-программТ-программа в режиме отладки прописывает в именованный pipe свой PID и ждет изменения некоторой своей переменной, а из среды разработки удаленно запуска- ются отладчики по SSH, которые присоединяются к процессам и взаимодействуют со средой (визуализируют код программы и воспринимают команды пользователя). Переключение между окнами отладчиков происходит через меню среды разработки XEmacs.
Поскольку XEmacs взаимодействует с отладчиком строго через поток ввода-вывода, то ему не важно, где и как запускается тот или иной отладчик. PID процесса.
Оттестирован также и способ, когда отладчик запускается только в случае про- граммной ошибки.
Отладка и трассировка Т-программТрассировка предполагает запись всех событий (обмен, выборка из очереди, ...), которые влияют на ход работы программы.
Т-система использует систему трассировки MPI, добавляя к ней некоторую дополнительную информацию (возникающую на SMP-уровне)
В книге Хоара ╬Взаимодействующие последовательные процессы© приводится (несложная) теорема о том, что если на входы каждого последовательного про- цесса при двух прогонах системы приходят одни и те же события, то поведение системы в целом будет также одинаковым.
Примеры вычислительных задач Примеры вычислительных задач Примеры невычислительных задач Примеры невычислительных задач GQL Graph Query Language Различные операции над графами: * Вычисление значения рекурсивной функции на деревьях * Инкрементальное вычисление функций (используя мемоизацию) * Поиск подграфа в графе Программа на языке TC (Т-система)
#include <tc.h>
#include <stdio.h>
#include <stdlib.h>
unsigned cfib (unsigned _n)
{
return _n < 2 ? _n : cfib(_n - 1) + cfib(_n - 2);
}
tfun void fib (unsigned _n, tout unsigned *_res)
{
if (_n < 20) {
*_res = cfib(_n);
} else {
tval unsigned res1, res2;
fib(_n - 1, &res1);
fib(_n - 2, &res2);
*_res = res1 + res2;
}
}
int tmain (int argc, char* argv[])
{
unsigned n;
tval unsigned res;
if (argc < 2) {
fprintf(stderr,
"Usage:\n"
"gr_fib <number>\n"
);
return -1;
}
n = (unsigned)atoi(argv[1]);
fib(n, &res);
printf("fib(%u) = %u\n", n, res);
return 0;
}
Аналоги Т-системы
Cilk
#include <cilk.h>
#include <cilk-lib.h>
#include <stdlib.h>
#include <stdio.h>
cilk int fib (int n)
{
if (n < 2)
return (n);
else {
int x, y;
x = spawn fib(n - 1);
y = spawn fib(n - 2);
sync;
return (x + y);
}
}
cilk int main (int argc, char *argv[])
{
int n, result;
if (argc != 2) {
fprintf(stderr, "Usage: fib [<cilk options>] <n>\n");
Cilk_exit(1);
}
n = atoi(argv[1]);
result = spawn fib(n);
sync;
printf("Result: %d\n", result);
return 0;
}
SISAL
Язык с однократным присваиванием
Компиляция в две стадии:
1. Генерация промежуточного года на C/FORTRAN с оптимизацией
2. Генерация выполняемого файла (стандартный C/FORTRAN компилятор)
Пример реализации быстрой сортировки на языке SISAL:
define Main
type Info = array[ integer ]
function Main (Data : Info returns Info)
function Split (
Data : Info returns Info, Info, Info)
for E in Data
returns array of E when E < Data[ 1 ]
array of E when E = Data[ 1 ]
array of E when E > Data[ 1 ]
end for
end function
%
% routine body
%
if array_size( Data ) > 2 then
let
L, Middle, R := Split( Data )
in
Main( L ) || Middle || Main( R )
end let
else
Data
end if
end function % quicksort
Параллельный Haskell
import Parallel
pfc :: Int -> Int -> Int -> Int
pfc x y c
| y - x > c = f1 `par`
(f2 `seq` (f1+f2))
| x == y = x
| otherwise = pf x m + pf (m+1) y
where
m = (x+y) `div` 2
f1 = pfc x m c
f2 = pfc (m+1) y c
pf :: Int -> Int -> Int
pf x y
| x < y = pf x m + pf (m+1) y
| otherwise = x
where
m = (x+y) `div` 2
parfact x c = pfc 1 x c