|

12. Архитектура системы обработки
информации при моделировании
сложных задач динамики судна на
волнении
Математическое моделирование
сложных задач динамики судна на
волнении связано с использованием
быстродействующей вычислительной
техники и параллельной обработки
информации. Такие требования
выполняются практически ко всем
рассмотренным выше методам
моделирования, особенно если их
реализация осуществляется в системе
реального времени (бортовая
интеллектуальная система анализа и
прогноза мореходных качеств судна и
параметров морского волнения и др.).
Наиболее типичной является
задача моделирования методом
Монте-Карло, требующая большого
объема исходной информации для
последующей статистической
обработки. Ниже описаны аппаратурная
конфигурация и программирование
параллельной мультипроцессорной
системы, предназначенной для
моделирования различных задач
динамики судна на волнении методом
Монте-Карло. Основные элементы
системы: центральный компьютер, три
жестко связанных параллельных
процессора с локальными модулями
памяти. Описываемая
мультипроцессорная система
обеспечивает гибкость в работе,
допускает наращивание и исполняет
программы, составленные на языке
высокого уровня. Центральный
компьютер используется для отладки,
компилирования и пересылки в
подчиненные процессоры программ, а
также для передачи результатов
моделирования из рабочей памяти на
внешние носители информации для
последующего анализа.
Мультипроцессорная система
моделирования методом Монте-Карло
представлена на рис.1.20. В системе
можно выделить три основных элемента:
центральный компьютер с памятью, три
параллельных процессора Монте-Карло
(МК-процессоры) и рабочие модули
памяти этих процессоров. Центральный
компьютер используется для
редактирования, компиляции и
загрузки программ в МК-процессоры.
Архитектура комплекса построена на
двух раздельных шинах: общей и локальной шине, что позволяет
легко его наращивать. Общая шина
избрана для обеспечения
совместимости с компьютером. Она
представляет собой асинхронный
мультиплексный канал связи,
предназначенный для обмена данными
между одноплатными расширенными
модулями с максимальной частотой.
Для связи между центральным
компьютером и МК-процессорами
выбрана традиционная архитектура
общей шины, обеспечивающая простоту
расширения комплекса. Система
расширения локальной шины - это
специализированный канал,
позволяющий значительно улучшить
характеристики комплекса. Каждый из
МК-процессоров имеет свою локальную
шину, подключенную к своей особой
рабочей памяти.
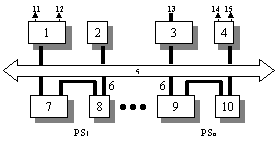
Рис.1.20. Архитектура
мультипроцессорной системы: 1 -
центральный компьютер; 2 -
оперативная память центрального ком-пьютера;
3 - контроллер жесткого диска; 4 -
модуль расширения для
последовательных каналов; 5 - общая
шина; 6 - локальная шина; 7,9 -
параллельный процессор; 8, 10 - ОЗУ
параллельного процессора; 11 -
терминал; 12 - принтер; 13 - жесткий диск; 14 -
графопостроитель; 15 - сеть; PS1,:, PSn
- параллельные структуры
Мультиплексорный
комплекс организован как система с нежесткими
связями. Каждый из МК-процессоров
оснащен своим динамическим
запоминающим устройством и
предназначен для решения конкретной
задачи. Для модулей памяти выбраны
совместимые с шинами платы,
содержащие быстродействующую
сверхоперативную память. Это
позволяет значительно снизить
среднее время доступа к памяти в
случае многократных повторных
обращений к одним и тем же адресам (например,
в программных циклах).
Моделирующие МК-процессоры
базируются на параллельных
процессорах,
использующих специфику
моделирования методом Монте-Карло.
При выборе МК-процессоров основное
внимание обращается на гибкость и
быстродействие. Повышение
быстродействия достигается за счет
параллельной архитектуры и
конвейерной обработки данных в
пределах каждого процессора. Для
обеспечения гибкости
предусматривается реализация
программного комплекса на языке
высокого уровня. Блок-схема МК-процессора
представлена на рис.1.21.
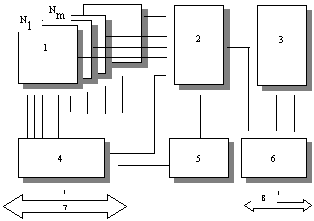
Рис.1.21.
Блок-схема параллельных процессоров:
1 - моделирующие
процессоры; 2 - адресный процессор; 3 -
сверхоперативная память; 4 - главный
процессор; 5 - общая логика управления;
6 - интерфейс к рабочей памяти; 7 -
общая шина; 8 - локальная шина; N1,
Nm
- параллельные микропроцессоры
Каждый МК-процессор
на этой схеме представляет собой
пакет из восьми микропроцессоров,
подключенных к общей внутренней шине
данных. МК-процессор имеет два
основных режима работы: режим
главного процессора и параллельный
режим. В непараллельном режиме главного
процессора происходит обмен
информацией с центральным
компьютером и семью подчиненными
микропроцессорами. При этом
оставшиеся семь микропроцессоров
ожидают загрузки программ. В параллельном
режиме каждый из
обрабатывающих элементов (ОЭ)
исполняет свою программу независимо
от остальных. Однако для
обслуживания запросов на операции
ввода/вывода используется простая
кольцевая схема. В результате чего ОЭ
в МК-процессоре становятся жестко
связанными.
Первый из ОЭ (главный
ОЭ) имеет доступ к общей
шине и распространяет программы и
исходные значения параметров от
центрального процессора в семь
остальных микропроцессоров. Кроме
того, главный ОЭ собирает результаты
вычислений и передает их в
центральный компьютер. При
инициализации системы главный ОЭ
выполняет двухэтапную первичную
загрузку подчиненных процессоров,
так как остальные ОЭ имеют
программную память лишь
минимального объема (для снижения
числа компонентов). В ходе
последовательности первоначального
запуска главный процессор передает в
подчиненные
процессоры специализированную
информацию, необходимую для
распределения задач. После
инициализации подчиненные ОЭ
работают под управлением своих
мониторных программ и готовы к
приему прикладных программ.
Аппаратные элементы
главного процессора показаны на рис.1.22.
Ниже рассмотрены назначение и
реализация этих элементов.
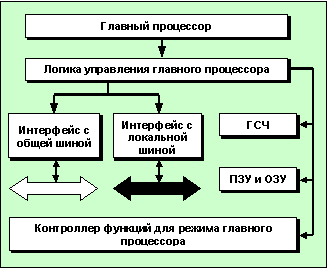
Рис.1.22.
Блок-схема главного процессора
Интерфейс главный микропроцессор -
общая шина представляет собой
программу в ПЗУ, обеспечивающую
обмен параметрами и засылку программ,
а также передачу диагностической
информации в центральный компьютер.
Все эти функции выполняются через
два адреса в адресном пространстве
шины. Каждый МК-процессоров занимает
два адреса на общей шине. Через
первый из них передаются программы и
параметры, а через второй -
центральный компьютер считывает
диагностическую информацию и
информацию о состоянии МК-процессора.
В режиме главного
процессора главный ОЭ полностью
управляет остальными
функциональными элементами МК-процессора.
Управление этими функциями
обеспечивает контроллер режима главного процессора.
Например, главный ОЭ может прерывать
подчиненные для считывания записи
данных или передавать в них
сигналы сброса для синхронизации
или занесения программ. Другая
важная функция контроллера состоит в
возможности обмена данными с
регистрами адресного процессора.
Таким образом, главный ОЭ может
инициализировать процессор адресов
перед исполнением программы.
Предусмотрено также управление
сверхоперативной памятью
посредством считывания и записи
данных через локальную шину МК-процессора.
Обеспечение быстродействия
каждого процессора достигается
также за счет использования
быстродействующего генератора
случайных чисел (ГСЧ). Устранение <узкого места>
для скорости моделирования
обеспечивается путем использования
для каждого ОЭ своего ГСЧ. При этом
ГСЧ реализуется двумя способами -
аппаратным и программным.
Программная версия составляется
непосредственно в кодах МК-процессора.
Аппаратная реализация
обеспечивается благодаря применению
специализированнной интегральной
схемы, позволяющей вырабатывать
новое псевдослучайное число в каждом
такте синхронизации. В результате
высвобождается больше места для
прикладных программ в МК-процессоре.
В состав каждого из подчиненных
процессоров
входят процессор сигналов,
программное запоминающее устройство,
генератор случайных чисел,
логические схемы управления
обменами и два вентиля для связи с
локальной шиной. Все подчиненные ОЭ
подключены к локальной шине, а каждый
элемент имеет вход подтверждения для
получения сигналов от локальной шины
(рис.1.23).
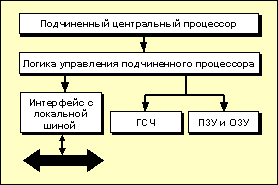
Рис.1.23.
Блок-схема модуля подчиненного
центрального процессора
Микропрограммный процессор
адресов (рис.1.24) рассчитывает все адреса памяти
для восьми ОЭ. В каждой интегральной
схеме имеются каналы для хранения
раздельных адресов чтения и записи
каждого из ОЭ. Один из процессоров
вырабатывает адреса Х, а другой -Y.
Адреса Х и Y соответствуют
координатам в двумерной решетке,
подлежащей моделированию методом
Монте-Карло. Вычисление каждого
очередного адреса базируется на
предшествующем значении. Процессор
адресов позволяет уменьшать или
увеличивать адреса на единицу или
добавлять фиксированное смещение по
обоим направлениям. Таким образом, в
рабочую память могут быть занесены
произвольные условия преобразования
информации в соответствии с режимом
работы. Адресный процессор
обеспечивает предварительную
выборку данных для рабочей памяти.
При этом используется
зафиксированный адрес следующего
элемента. Этим задается жестко
детерминированный порядок обращения
ОЭ к общей шине данных. Для
предварительной обработки требуется
информация о следующем адресе,
которая передается через адрес порта
ввод/вывода в процессе
предшествующего такта считывания.
Рабочий цикл процессора адресов
начинается аналогичным образом для
всех операций ввода/ вывода с
использованием сохраняемых адресов
всех ОЭ поочередно. Если данные
хранятся в сверхоперативной памяти,
то их можно считать сразу в связи с
обеспечением времени обращения к
этой памяти и быстродействия логики
сравнения адресов. Процессор адресов
выделяет шину данных для конкретного
ОЭ. Однако до тех пор, пока ОЭ не
начнет работать с шиной, невозможно
узнать, какая операция (ввод или
вывод) выполняется. При выполнении
операции ввода ОЭ игнорирует
предварительно извлеченные данные и
начинает нормальный цикл записи на
локальной шине. Если данные не были
занесены в сверхоперативную память,
адресный процессор исполняет полную
операцию считывания и занесения в
сверхоперативную память для
следующего ОЭ.
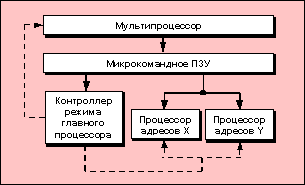
Рис.1.24.
Блок-схема модуля адресного
процессора
Алгоритм моделирования Монте-Карло
может исполняться как с
последовательным, так и со случайным
изменением состояний. В связи с этим
можно реализовать два режима работы сверхоперативной
памяти:
синхронный и случайный (рис.1.25). В
обоих режимах необходимо считывать
во внутренную память ОЭ все
окружение текущего обрабатываемого
элемента. Повышение быстродействия
благодаря использованию
сверхоперативной памяти весьма
существенно для обеспечения
эффективной работы системы,
построенной на базе общей шины.
В синхронном режиме максимальная
эффективность использования
сверхоперативной памяти достигается
путем применения в ОЭ построчной
обработки информации. В этом случае
достигается максимальное
перекрывание адресов. Каждый раз,
когда происходит считывание слова из
рабочей памяти, адресный процессор
заносит его в сверхоперативную
память. Если соседнему ОЭ требуются
эти же данные, то они будут быстро
получены. При этом работа
сверхоперативной памяти оказывается
весьма простой, так как возможно
прямое отображение ряда
последовательных строк из рабочей
памяти на сверхоперативную. При
операциях вывода данные заносятся
непосредственно либо в рабочую, либо
в сверхоперативную память.
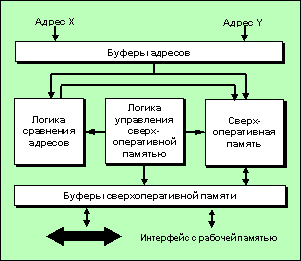
Рис.1.25.
Блок-схема сверхоперативной памяти
При моделировании методом Монте-Карло
необходимо использовать случайный порядок обхода
решетки. В этом случае окружения двух
или более позиций в решетке могут
перекрываться, в результате чего
могут возникать конфликтные
ситуации: один
из ОЭ будет уточнять состояние в
некоторой точке в тот же момент,
когда другой ОЭ будет использовать
эту информацию в качестве
обрамляющей. В режиме случайной
выборки последовательность работы
управляющей логики сверхоперативной
памяти необходимо изменить: вместо
того, чтобы сразу принимать данные из
сверхоперативной памяти,
использовать информацию о
зафиксированных битах для
блокировки работы ОЭ до их
стабилизации. Для этого требуется
лишь один адресный маркер, так как
недействительные маркеры
сбрасываются при каждом обнаружении.
ОЭ может продолжать свою работу в
следующем такте, если только вновь не
возникнет конфликт. Такое
использование сверхоперативной
памяти позволяет организовать
механизм блокировки процессоров в
системе с разделяемой памятью. В
случайном режиме обхода решетки,
когда следующий адрес считывания
невозможно определить наперед,
использование сверхоперативной
памяти не дает существенного
повышения быстродействия МК-процессора.
Подчиненный процессор в активном
состоянии использует три командные
линии для инициализации обмена
данными, управления ими и их
завершения. Интерфейс рабочей памяти обеспечивает сигнал
подтверждения, прежде чем приступить
к следующему обмену. Кроме того,
интерфейс реализует арбитраж
доступов к двухпортовой памяти.
Блокируя доступ через
альтернативный порт, МК-процессор
гарантирует, что общие данные в
разделяемой рабочей
памяти не будут распространяться
до тех пор, пока активный МК-процессор
не завершит свою работу с ними.
Блок тактовых сигналов
обеспечивает синхронизацию всех
процессов, Тактовые сигналы - общие
для всех процессов, так что все
инструкции выполняются одновременно.
Все ОЭ работают синхронно, поскольку
тактовые сигналы управляются
цифровыми контурами фазовой
синхронизации, что позволяет
скомпенсировать температурные
дрейфы. Все функциональные элементы
системы, подключенные к локальной
внутренней шине МК-процессора,
рассчитаны на оптимальный режим
работы. Поэтому все запросно-подтверждающие
и иные необходимые сигналы
синхронизации обменов между двумя
функциональными элементами
сосредоточены в общем управляющем
блоке. Для повышения функциональной
плотности используются
программируемые логические матрицы.
Реализация параллельных
алгоритмов основана на методике
разбиения, по которой каждому ОЭ
выделяется область рабочих данных.
Поскольку МК-процессор работает по
принципу МИМД, большинство
составленных для него программ
оптимизированы для работы в режиме
МИМД, т.е. каждый поток данных,
используя общие для всех инструкции.
В этом случае составляется общая
программа с учетом того, что
параллельные вычисления требуют
задания разных смещений для
распределения рабочих областей
данных.
При программировании по принципу
МИМД, когда программы разных ОЭ
различаются, необходимо задавать а
программные блоки с условным
использованием, в зависимости от
идентифицирующих
последовательностей ОЭ, которые
различны для всех процессоров. Эти
последовательности заносятся в ОЭ во
время первоначальной загрузки.
Многие из прикладных программ
обеспечивают вполне
удовлетворительную работу без
взаимообмена между ОЭ. Вместе с тем, в
некоторых случаях могут
потребоваться итеративные программы,
использование которых будет
зависеть от глобальных свойств
рабочей памяти. В этих случаях
возникает необходимость в еще одной
программе, которая исполняется
только в главном ОЭ. Назначение этой
программы - сбор промежуточных
результатов от остальных ОЭ, их
обработка и иные манипуляции.
Результаты можно вывести в
центральный компьютер для
последующего анализа. Эти операции
управляются мониторной программой
МК-процессора и управляющей
программой центрального компьютера.
В
состав пакета программ, необходимых
для работ с системой, входят
компилятор с принятого языка
программирования, программа
управления МК-процессором и
мониторная программа, которые
заносятся в ПЗУ МК-процессора.
Таким
образом, моделирующие программы
обеспечивают почти полное
распараллеливание, а объем обменов
между процессорами весьма невелик.
Оптимальность системы ограничивают
два фактора: доступ к данным от
каждого из ОЭ и прикладное
программное обеспечение. Для
получения максимальной
производительности необходимо
распределить инструкции ввода/вывода
как можно более равномерно по
программе.
|

